

Developer-Centric AI: Vector Databases and our Investment in Weaviate
Just as MongoDB unlocked a whole ecosystem of cloud-native applications, vector databases are unlocking the market for AI-native applications.

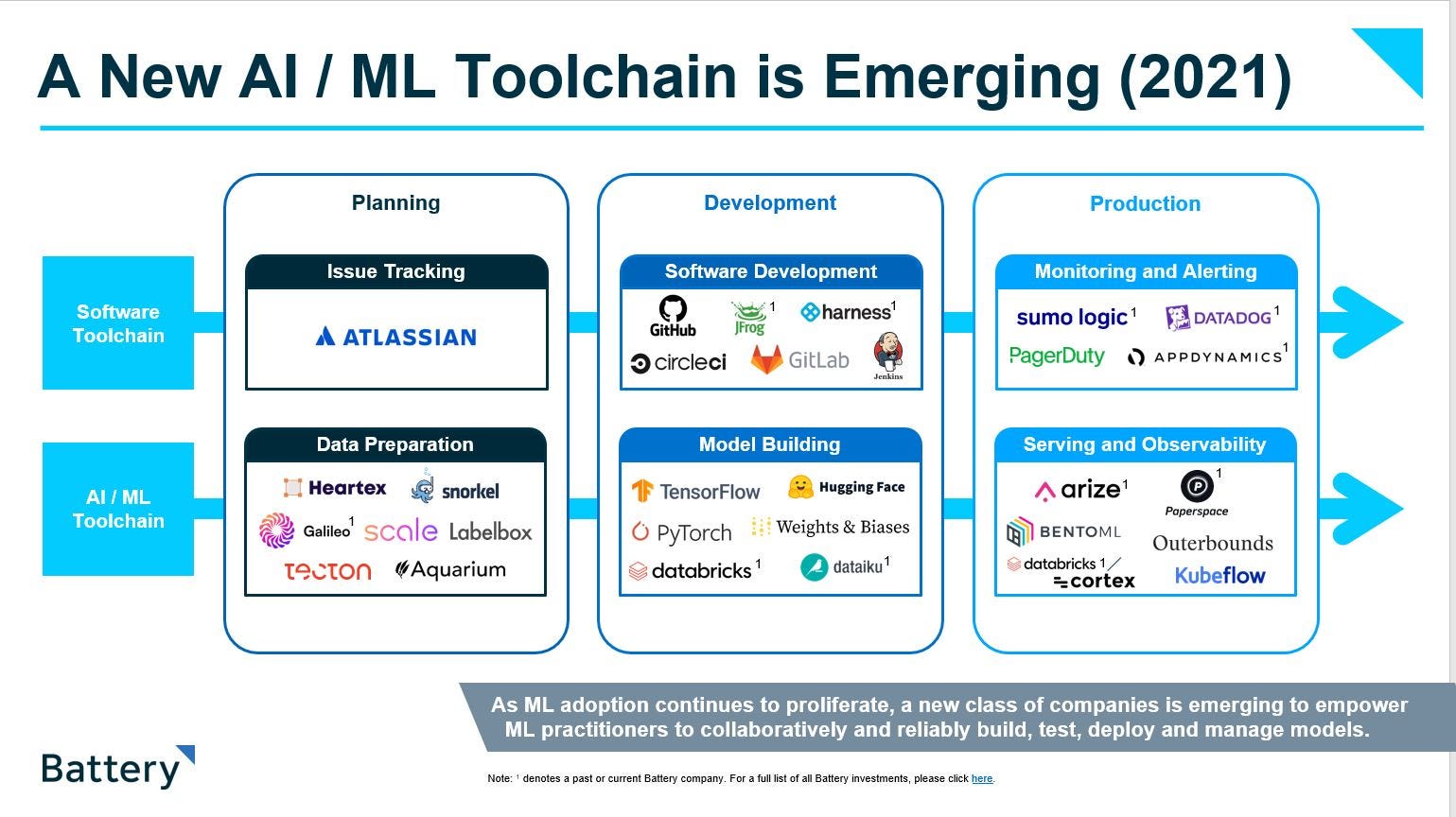
In our 2021 OpenCloud report, we discussed our thesis that the artificial intelligence (AI) and machine learning (ML) toolchain was evolving in a similar way to the software-development stack—with specific tools for planning, development and production. What we didn’t say at that time was that ultimately, this means software developers likely will become core to unleashing the potential of AI to consumers and enterprises alike.
The advent of AI can be traced back before the 2017 release of the seminal academic paper called Attention is All You Need – to an earlier time when this technology was only available and accessible to research institutions or giant, hyper-scale tech companies such as Amazon, Google, Facebook and Netflix.
As access to data among enterprises increased, a new crop of companies emerged to bridge the development gap of AI through a new framework called MLOps. The broad category of MLOps was derived from core DevOps principles: MLOps ensures repeatable, reusable and consistent practices across the ML-development workflow. This workflow was particularly effective for predictive AI use cases, or the practice deriving predictions about future events based on historical data using supervised ML algorithms.
Since then, generative AI emerged as a way to create new data artifacts from existing data. Examples include creating images, music, text, code or any other form of data through unsupervised or semi-supervised ML techniques. This brought with it a paradigm shift in the way that software could be built and run as foundation models democratize access to powerful AI capabilities and unlock an entirely new set of workflows and use cases.
The result is that AI evolved from a specialized industry of researchers, data scientists and machine learning engineers to a broader category accessible to designers, writers, business users and software developers.
Developer-centric AI has been crucial to this transition, with a new technology stack emerging to support generative AI. Although MLOps tools remain relevant, the landscape has significantly changed, reflecting the growing importance of developers in the AI domain going forward.
Battery Ventures’ 2023 Generative-AI stack
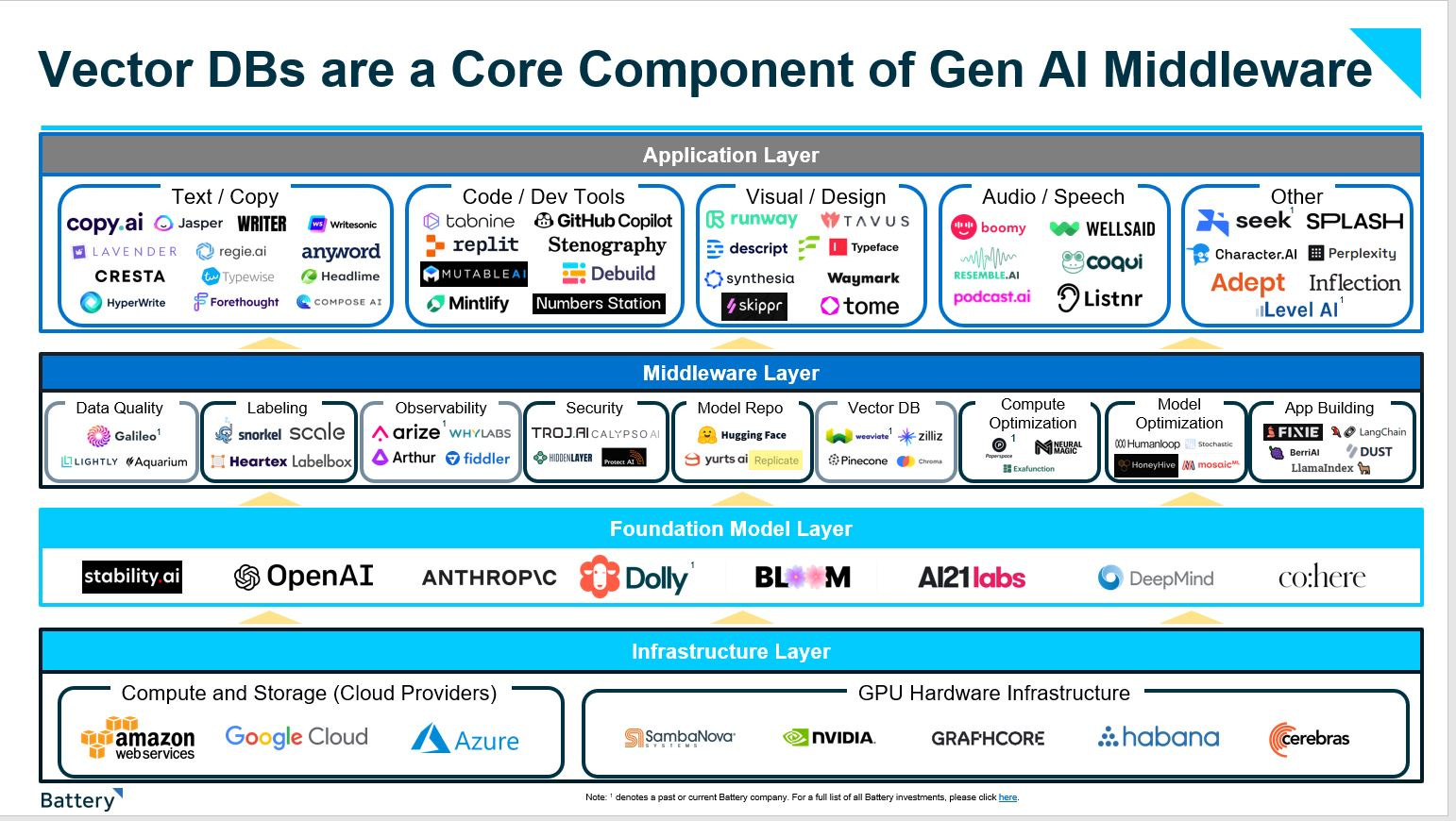
Why now?
Despite the excitement around generative-AI middleware from developers and business users alike, there is still a fundamental tooling gap between foundation models and the application layer, especially within the enterprise. While foundation models provide a high-level of abstraction, they are trained on generalized data across the internet and have a defined timeframe for retrieval. They lack use case/company-specific data and don’t allow users to easily integrate them into their internal databases and systems (i.e., they sit behind the walls of the foundation model provider).
Similarly, the volume of complex, unstructured and semi-structured data is also growing at a rapid pace. Traditional databases that were built for structured data are unable to process, store and analyze these complex data types at volume. To solve this problem, vector databases have emerged as the AI-native architecture to solve enterprise-data access and foundation-model tuning challenges.
At the heart of a vector database are vector embeddings, which represent a new type of data format that allows users to describe data objects as numeric values in hundreds or thousands of different dimensions. Vector embeddings have become the building blocks for many ML and deep-learning algorithms. ML models, like software applications, typically require human readable inputs (text, audio, images) to be converted into machine-readable inputs (vector embeddings). Further, vector embeddings allow users to add structure to complex unstructured/semi-structured data, preserving the data’s original context/meaning. Despite Word2Vec by Google being early in making vector embeddings available, it wasn’t until the release of embedding specific models by OpenAI, Cohere and Hugging Face that vector embeddings became universally accessible.
While vector databases were originally developed to address needs of large-scale personalization, recommendation and semantic search/retrieval engines, today we’ve seen new use cases emerge around data clustering, anomaly detection and proprietary data retrieval—with real-world applications in sectors as varied as Internet search, sales analysis and cybersecurity.

As the volume of unstructured data continues to expand, vector databases play an increasingly critical role in enabling users to search through relationships, context and meaning. Many of these use cases aren’t necessarily new and have been solved in the past with retrieval and search systems such as Elasticsearch, OpenSearch, Solr and Lucene. But simply supporting different indexing libraries on rigid data models that don’t support CRUD operations and store raw data objects and metadata with vectors isn’t enough. In a data-driven world, enterprises want to maintain control of their proprietary data, and vector databases serve as a critical component to enable better model creation with proprietary use case/domain-specific data.
Data-platform shifts require new databases
With every new data-platform shift there is a new database that developers and enterprises adopt. While this is not a perfect representation of these platform shifts, it’s a heuristic to capture technology transitions that unlock new use cases and applications.

The transition from mainframe computers to personal computing led to the rise in structured data and, as a result, relational databases such as MySQL, Postgres, Oracle and Microsoft SQL Server.
The internet led to the explosion of unstructured and non-tabular data such as user fields and document-model data formats that were native to cloud applications, resulting in NoSQL databases such as MongoDB, Couchbase and Elasticsearch.
The emergence of “big data” within enterprises ushered in cloud-data warehouses for storing, managing and analyzing large volumes of structured and semi-structured data and the formation of Redshift, Snowflake, Redshift, BigQuery and Databricks’* DeltaLake.
As more enterprises and developers adopt, embed and build AI-native applications, which rely on this new embedding data-model, we believe vector databases will emerge as the new database to support these workloads, use cases and applications. Just as MongoDB unlocked a whole ecosystem of cloud-native applications, vector databases are unlocking the market for AI-native applications.
Our investment in Weaviate*
Today, we are announcing our investment in Weaviate, alongside Index Ventures, NEA, Cortical Ventures, Zetta Venture Partners and ING Ventures. The vector-database landscape has exploded over the last year with purpose-built vector stores like Weaviate and traditional database vendors like Mongo, Postgres, Elastic and Redis announcing support for vectors. Weaviate sets itself apart by storing both the core data object and vectors alongside each other, enabling its customers to combine vector search with structured filtering and the fault tolerance of a cloud-native database for application developers.
Weaviate is led by Bob van Luijt, who has built a very large community around Weaviate from the ground up. As an open-source, developer-focused database, Weaviate has a lot of parallels to MongoDB and Elastic, which also captured developer affinity through an open source-led motion. MongoDB started as an on-prem database but later added cloud support (based on their most recent earnings release, Mongo’s Atlas product now boasts a ~$940M run-rate and represents 65% of Mongo’s total quarterly revenue), which enabled the company to rapidly scale monetization by abstracting infrastructure complexity and focusing on ease-of-use. Weaviate has a similar motion (open-source and developer-first) but has made a concerted effort to build a cloud-native product upfront. We believe this cloud-first mentality will unlock a faster path to monetization and enterprise customer adoption.
We are excited to partner with Weaviate as the company brings its AI-native databases to application developers, unlocking the next wave of innovation for all. We look forward to this next chapter of growth.
This material is provided for informational purposes, and it is not, and may not be relied on in any manner as, legal, tax or investment advice or as an offer to sell or a solicitation of an offer to buy an interest in any fund or investment vehicle managed by Battery Ventures or any other Battery entity.
The information and data are as of the publication date unless otherwise noted.
Content obtained from third-party sources, although believed to be reliable, has not been independently verified as to its accuracy or completeness and cannot be guaranteed. Battery Ventures has no obligation to update, modify or amend the content of this post nor notify its readers in the event that any information, opinion, projection, forecast or estimate included, changes or subsequently becomes inaccurate.
The information above may contain projections or other forward-looking statements regarding future events or expectations. Predictions, opinions and other information discussed in this video are subject to change continually and without notice of any kind and may no longer be true after the date indicated. Battery Ventures assumes no duty to and does not undertake to update forward-looking statements.
*Denotes a Battery portfolio company. For a full list of all Battery investments, please click here.
Great read. Thanks for putting together Danel.
Mongo’s Atlas is at 940B run-rate ? Or 940M